Metode Pencarian dan Pelacakan 2 (Heuristik)
Metode Pencarian dan Pelacakan 2
(Heuristik)
Heuristik adalah sebuah teknik yang
mengembangkan efisiensi dalam proses pencarian, namum dengan kemungkinan
mengorbankan kelengkapan (completeness).
Fungsi heuristik digunakan untuk mengevaluasi keadaankeadaan
problema individual dan menentukan seberapa jauh hal tersebut dapat digunakan
untuk mendapatkan solusi yang diinginkan.
Jenis-jenis Heuristic Searching:
1. Best First Search.
2. Problem Reduction
3. Constraint Satisfaction 5.4 Means End Analysis
4. Means End Analysis
5.1 PENCARIAN TERBAIK PERTAMA(Best-First
Search)
Metode ini merupakan kombinasi dari metode
depth-first search dan breadth-first search. Pada metode best-first search,
pencarian diperbolehkan mengunjungi node yang ada di level yang lebih rendah,
jika ternyata node pada level yang lebih tinggi ternyata memiliki nilai
heuristic yang lebih buruk.
Fungsi
Heuristik yang digunakan merupakan prakiraan (estimasi) cost dari initial state
ke goal state, yang dinyatakan dengan :
f’(n)
= g(n)+ h’(n)
dimana
f’ = Fungsi evaluasi
g
= cost dari ini tial state ke current state
h’
= prakiraan cost dari current state ke goal state
Contoh
:
Misalkan
kita memiliki ruang pencarian seperti pada gambar dibawah. Node M merupakan
keadaan awal dan node T merupakan tujuannya. Biaya edge yang menghubungkan node
M dengan node A adalah biaya yang dikeluarkan untuk bergerak dari kota M ke
kota A. Nilai g diperoleh berdasarkan biaya edge minimal. Sedangkan nilai h’ di
node A merupakan hasil perkiraan terhadap biaya yang diperlukan dari node A
untuk sampai ke tujuan. h’(n) bernilai ~ jika sudah jelas tidak ada hubungan
antara node n dengan node tujuan (jalan buntu). Kita bisa mengurut nilai untuk
setiap node.


5.2
Problem Reduction
Problem reduction atau yang biasa dikenal
dengan constraint, intinya adalah berusaha mengurangi masalah dengan harapan
masalah yang bersangkutan menjadi lebih mudah diselesaikan. Sekarang ini sudah
diketahui teknik konsistensi ini sangat penting dalam penyelesaian constraint
satisfactionproblem yang sangat berat sehingga semua aplikasi komersial
penyelesaian constraint satisfactionproblem menggunakan teknik
konsistensi ini sebagai langkah dasar. Sejarah konsistensi constraint dapat
ditlusuri dari peningkatan efisiensi program pengenalan gambar oleh peneliti di
intelejensi semu. Pegenalan gambar melibatkan pemberian label kepada semua
garis pada gambar dengan cara yang konsisten. Jumlah kombinasi pemberian label
pada garis yang memungkinkan dapat menjadi sangat besar, sementara hanya
sedikit yang konsisten pada tahap awal. Dengan demikian memperpendek pencarian
untuk pembeian nilai yang konsisten.Untuk mengilustrasikan teknik konsistensi
ini akan diberikan sebuah contoh constraint satisfaction problem yang
sangat sederhana.
Anggap
A < B adalah constraint antara variabel A
dengan domainDA = { 3..7} dan variabel B dengan domain
DB = { 1..5}. dengan jelas tampak bahwa bahwa untuk sebagian nilai
pada DA tidak ada nilai yang konsisten di DB yang
memenuhi constraint A < B dan sebaliknya. Niai yang demikian dapat
dibuang dari domain yang berkaitan tanpa kehilangan solusi apapun.
Reduksi itu aman. Didapatkan domain yang tereduksi DA =
{3,4} dan DB = {4,5}.
Perhatikan
bahwa reduksi ini tidak membuang semua pasangan yang tidak konsisten. Sebagai
contoh kumpulan label (<A, 4>, <B, 4>) masihh dapat dihasilkan
dari domain, tetapi untuk setiap nilai A dari DAadalah
mungkin untuk mencari nilai B yang konsisten dan sebaliknya.
Walaupun
teknik konsistensi ini jarang digunakan sendirian untuk menghasilkan solusi,
teknik konsistensi ini membantu menyelesaikan constraint
satisfactionproblem dalam beberapa cara. Teknik konsistensi ini dapat
dipakai sebelum pencarian maupun pada saat pencarian.
Constraint sering
direpresentasikan dengan gambar graf (gambar 1) di mana setiap verteks mewakili
variabel dan busur antar verteks mewakili constraint binari yang
mengikat variabel-variabel yan dihubungkan dengan busur tersebut. Constraint unari
diwakilkan dengan busur melingkar.
Kebanyakan
solusi menggunakan pohonOR,dimana lintasan dari awal sampai tujuan tidak
terletak pada satu cabang. Bila lintasan dari keadaan awal sampai tujuan dapat
terletak pada satu cabang, maka kita akan dapat menemukan tujuan lebih cepat.
Graf
AND-OR
Pada
dasarnya sama dengan algoritma Best First Search, dengan mempertimbangkan
adanya arc AND. Gambar berikut menunjukkan bahwa untuk mendapatkan TV orang
bisa dengan cara singkat yaitu mencuri atau membeli asal mempunyai uang.Untuk
mendeskripsikan algoritma, digunakan nilai F_UTILITY untuk biaya solusi.
Untuk
mendeskripsikan algoritma Graph AND-OR kita menggunakan nilai F_UTILITY, yaitu
biaya solusi.
Algoritma:
1. Inisialisasi
graph ke node awal.
2. Kerjakan
langkah-langkah di bawah ini hingga node awal SOLVED atau sampai biayanya lebih
tinggi dari F_UTILITY:
(a.) Telusuri
graph, mualai dari node awal dan ikuti jalur terbaik. Akumulasikan kumpulan
node yang ada pada lintasan tersebut dan belum pernah diekspansi atau diberi
label SOLVED.
(b.) Ambil
satu node dan ekspansi node tersebut. Jika tidak ada successor, maka set
F_UTILITY sebagai nilai dari node tersebut. Bila tidak demikian, tambahkan
successor-successor dari node tersebut ke graph dan hitung nilai setiap f’
(hanya gunakan h’ dan abaikan g). Jika f’ = 0, tandai node tersebut dengan
SOLVED.
(c.) Ubah
f’ harapan dari node baru yang diekspansi. Kirimkan perubahan ini secara
backward sepanjang graph. Jika node berisi suatu arc suatu successor yang semua
descendant-nya berlabel SOLVED maka tandai node itu dengan SOLVED.
Pada
Gambar 2.33, pada langkah-1 semula hanya ada satu node yaitu A. Node A
diekspansi hasilnya adalah node B, C, dan D. Node D memiliki biaya
yang lebih rendah (6) jika dibandingkan dengan B dan C (9). Pada langkah-2 node
D terpilih untuk diekspansi, menjadi E dan F dengan biaya estimasi sebesar 10.
Sehingga kita harus memperbaiki nilai f’ dari D menjadi 10. Kembali ke level
sebelumnya, node B dan C memiliki biaya yang lebih rendah daripada D (9 <
10). Pada langkah-3, kita menelusuri arc dari node A, ke B dan C bersama-sama.
Jika B dieksplore terlebih dahulu, maka akan menurunkan node G dan H. Kita
perbaiki nilai f’ dari B menjadi 6 (nilai G=6 lebih baik daripada H=8), sehingga
biaya AND-arc B-C menjadi 12 (6+4+2). Dengan demikian nilai node D kembali
menjadi lebih baik (10 < 12). Sehingga ekspansi dilakukan kembali terhadap
D. Demikian seterusnya.

Algoritma
AO* menggunakan struktur Graph. Tiap-tiap node pada graph tersebut akan
memiliki nilai h’ yang merupakan biaya estimasi jalur dari node itu sendiri
sampai suatu solusi.
Algoritma
1. Diketahui
GRAPH yang hanya berisi node awal (sebut saja node INIT). Hitung
h’(INIT).
2. Kerjakan
langkah-langkah di bawah ini hingga INI bertanda SOLVED atau samoai nilai
h’(INIT) menjadi lebih besar daripada FUTILITY:
(a) Ekspand
INIT dan ambil salah satu node yang belum pernah diekspand (sebut NODE).
(b) Bangkitkan
successor-successor NODE. Jika tida memiliki successor maka set FUTULITY dengan
nilai h’(NODE). Jika ada successor, maka untuk setiap successor (sebut sebagai
SUCC) yang bukan merupakan ancestor dari NODE, kerjakan:
i Tambahkan
SUCC ke graph.
ii Jika
SUCC adalah terminal node, tandai dengan SOLVED dan set nilai h’-nya sama dengan
0.
iii Jika
SUCC bukan terminal node, hitung nilai h’.
(c) Kirimkan
informasi baru tersebut ke graph, dengan cara: tetapkan S adalah node yang
ditandai dengan SOLVED atau node yang nilai h’-nya baru saja diperbaiki, dan
sampaikan nilai ini ke parent-nya. Inisialisasi S = NODE. Kerjakan langkah-langkah
berikut ini hingga S kosong:
i Jika
mungkin, seleksi dari S suatu node yang tidak memiliki descendant dalam GRAPH
yang terjadi pada S. Jika tidak ada, seleksi sebarang node dari S (sebut:
CURRENT) dan hapus dari S.
ii Hitung
biaya tiap-tiap arc yang muncul dari CURRENT. Biaya tiap-tiap arc ini sama
dengan jumlah h’ untuk tiap-tiap node pada akhir arc ditambah dengan biaya arc
itu sendiri. Set h’(CURRENT) dengan biaya minimum yang baru saja dihitung dari
stiap arc yang muncul tadi.
iii Tandai
jalur terbaik yang keluar dari CURRENT dengan menandai arc yang memiliki biaya
minimum.
iv Tandai
CURRENT dengan SOLVED jika semua node yang dihubungkan dengannya hingga arc
yang baru saja ditandai tadi telah ditandai dengan SOLVED.
v Jika
CURRENT telah ditandai dengan SOLVED atau jika biaya CURRENT telah berubah,
maka status baru ini harus disampaikan ke GRAPH. Kemudian tambahkan semua
ancestor dari CURRENT ke S.
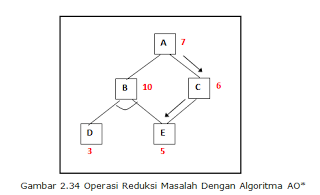
Sebagai
contoh, pada Gambar 2.34 Jelas bahwa jalur melalui C selalu lebih baik daripada
melalui B. Tetapi jika biaya node E muncul, dan pengaruh perubahan yang
diberikan ke node B tidak sebesar pengaruhnya terhadap node C, maka jalur
melalui B bisa jadi lebih baik. Sebagai contoh, hasil expand node E, misalkan
10, maka biaya node C menjadi 11 (10+1), dengan demikian biaya node A apabila
memilih jalur lewat C adalah 12 (11+1). Tentu saja akan lebih baik memilih
jalur melalui node B (11). Tapi tidak demikian halnya apabila kemudian node D
diekspan. Bisa jadi jalur dengan melalui node B akan lebih buruk lagi ketimbang
jalur dengan melalui node C.
5.3 Constraint Satisfaction
Problem search standart
- state adalah
"black box“
- setiap struktur data yang mendukung fungsi successor, fungsi heuristik dan tes goal.
CSP
- state didefinisikan sebagai variabel Xi dengan nilai dari domain Di – Tes goal adalah sekumpulan constraint yang menspesifikasikan kombinasi dari nilai subset variabel.
Contoh sederhana adalah
bahasa representasi formal.
CSP ini merupakan
algoritma general-purpose dengan kekuatan lebih daripada algoritma pencarian
standar.
Contoh : Pewarnaan
Peta

Variabel WA, NT, Q, NSW,
V, SA, T
Domain Di = {red,green,blue}
Constraints : daerah yang bertetangga dekat harus memiliki warna yang berbeda.
Contoh WA ≠ NT, atau (WA,NT) {(red,green),(red,blue),(green,red), (green,blue),(blue,red),(blue,green)}
Constraints : daerah yang bertetangga dekat harus memiliki warna yang berbeda.
Contoh WA ≠ NT, atau (WA,NT) {(red,green),(red,blue),(green,red), (green,blue),(blue,red),(blue,green)}
Solusi lengkap dan
konsisten, contoh : WA = red, NT = green,Q = red,NSW = green,V = red,SA =
blue,T = green
Constraint Graf
Binary CSP biner :
setiap constraint merelasikan dua variable
Graf Constraint : node adalah variabel, arc adalah constraint
Graf Constraint : node adalah variabel, arc adalah constraint

5.4 Means End Analysis
MEA
adalah strategi penyelesaian masalah yang diperkenalkan pertama kali dalam GPS
(General Problem Solver) [Newell & Simon, 1963]. Proses pencarian
berdasarkan ruang masalah yang menggabungkan aspek penalaran forward dan
backward. Perbedaan antara state current dan goal digunakan untuk mengusulkan
operator yang mengurangi perbedaan itu. Keterhubungan antara operator dan
perbedaan tsb disajikan sebagai pengetahuan dalam sistem (pada GPS dikenal
dengan Table of Connections) atau mungkin ditentukan sampai beberapa
pemeriksaan operator jika tindakan operator dapat dipenetrasi.
Contoh
OPERATOR first-order predicate calculus dan operator2 tertentu mengijinkan
perbedaan korelasi task-independent terhadap operator yang menguranginya. Kapan
pengetahuan ada tersedia mengenai pentingnya perbedaan, perbedaan yang paling
utama terpilih pertama lebih lanjut meningkatkan rata-rata capaian dari MEA di
atas strategi pencarian Brute-Force. Bagaimanapun, bahkan tanpa pemesanan dari
perbedaan menurut arti penting, MEA meningkatkan metode pencarian heuristik
lain (di rata-rata kasus) dengan pemusatan pemecahan masalah pada perbedaan
yang nyata antara current state dengan goal-nya.
SUMBER:



Komentar
Posting Komentar